들어가며
안녕하세요, 카카오뱅크 AI데이터프로덕트개발팀에서 보이스피싱 탐지 모델 개발을 담당하고 있는 Fyve입니다.
저희 팀은 소비자보호팀과 긴밀하게 협력하며 날로 정교해지고 조직적으로 진화하는 보이스피싱 위협으로부터 고객의 소중한 자산을 보호하기 위해 AI 기술을 연구하고 적용하는 데 힘쓰고 있습니다. 최근 카카오뱅크의 이러한 보이스피싱 대응 노력이 외부 언론을 통해서도 소개된 바 있는데요. 이 글에서는 해당 기사 이면에 있는 저희 팀의 치열한 기술적 고민과 실제 모델 설계 과정을 공유하고자 합니다.
특히 기존의 단일 거래(point) 분석 방식이 가진 한계를 넘어, 고객의 연속적인 행동 패턴(sequence)을 종합적으로 분석하는 새로운 패러다임으로 전환한 과정에 대해 중점적으로 설명드리겠습니다. 이를 통해 매일 수천만 건 이상의 고객 행동을 수십 밀리초(ms) 안에 실시간으로 분석하여 과거에는 놓칠 수 있었던 잠재적 위험 신호까지 선제적으로 포착하는 과정을 소개합니다.
탐지 패러다임의 전환
진화하는 위협으로 인한 기존 탐지의 한계
과거의 보이스피싱은 ATM 현금 인출, 고액 이체 등 특정 금융 거래(포인트)에서 발생하는 비교적 단순한 패턴을 보였습니다. 그러나 범죄 조직이 점점 더 체계화되고 기업화되면서, 그 수법 또한 예측하기 어려운 형태로 빠르게 진화하고 있습니다. 한 계좌에서 소액을 분할하여 거래를 하거나, 거래채널 다양화를 통해 편취 유형을 빠르게 변경하고, 가상자산 계좌를 활용하는 등 공격 방식이 더욱 교묘하고 다변화되고 있습니다.
이처럼 범죄 양상이 변화하면서, 사기가 발생하는 특정 거래 시점(포인트)만을 분석해 판단하는 기존 AI 모델의 한계가 분명해졌습니다. 이는 사건이 발생한 후에야 대응하는 ‘사후 대응’에 가까웠습니다. 또한 기존 AI 모델은 특정 보이스피싱 유형에 맞춰 변수를 가공(feature engineering)해야 했기 때문에 개발 비용이 많이 들고, 시시각각 변화하는 신종 사기 패턴을 선제적으로 막기에는 역부족이었습니다.
예를 들어, 과거에는 ATM 현금 인출 사기를 방지하기 위해 오랜 시간과 노력을 들여 여·수신 및 인구통계 변수들을 개발해 모델을 만들었습니다. 하지만 보이스피싱 유형이 이체 중심으로 바뀌면서 기존 모델로는 탐지하지 못하는 사각지대가 광범위하게 발생하는 문제를 겪게 되었습니다.
고객의 활동으로 구성된 시퀀스(sequence) 로 위험 신호를 예측
“한 번의 대형 사고가 발생하기 전에는 29번의 경미한 사고와 300번의 잠재적 위험 요인이 존재한다"는 하인리히 법칙(Heinrich’s Law) 처럼, 실제 보이스피싱 피해가 발생하기 전에도 반드시 여러 차례의 이상 징후가 고객의 행동에서 나타납니다. 저희는 바로 이 잠재적 위험 요인에 주목했습니다.
이를 위해 탐지 패러다임을 근본적으로 전환했습니다. 개별 거래(포인트)가 아닌 고객의 앱 이용 이력과 거래 내역 등 시간의 흐름에 따라 축적된 연속적인 행동 데이터, 즉 시퀀스(sequence) 전체를 분석하여 위험을 예측하는 새로운 모델을 개발했습니다. 이 시퀀스 기반 탐지 모델은 별도의 파생 변수 생성 없이 모델 구조만으로 보이스피싱의 징후를 시퀀스 안에서 탐지할 수 있습니다.
그 결과, 새로운 모델을 적용한 이후 기존 시스템으로는 포착하기 어려웠던 잠재적 위험 시퀀스를 탐지하고 피해를 예방하는 등 가시적인 성과를 거두고 있습니다.
시퀀스 기반 탐지 모델의 접근 방식
포인트가 아닌 시퀀스로의 접근
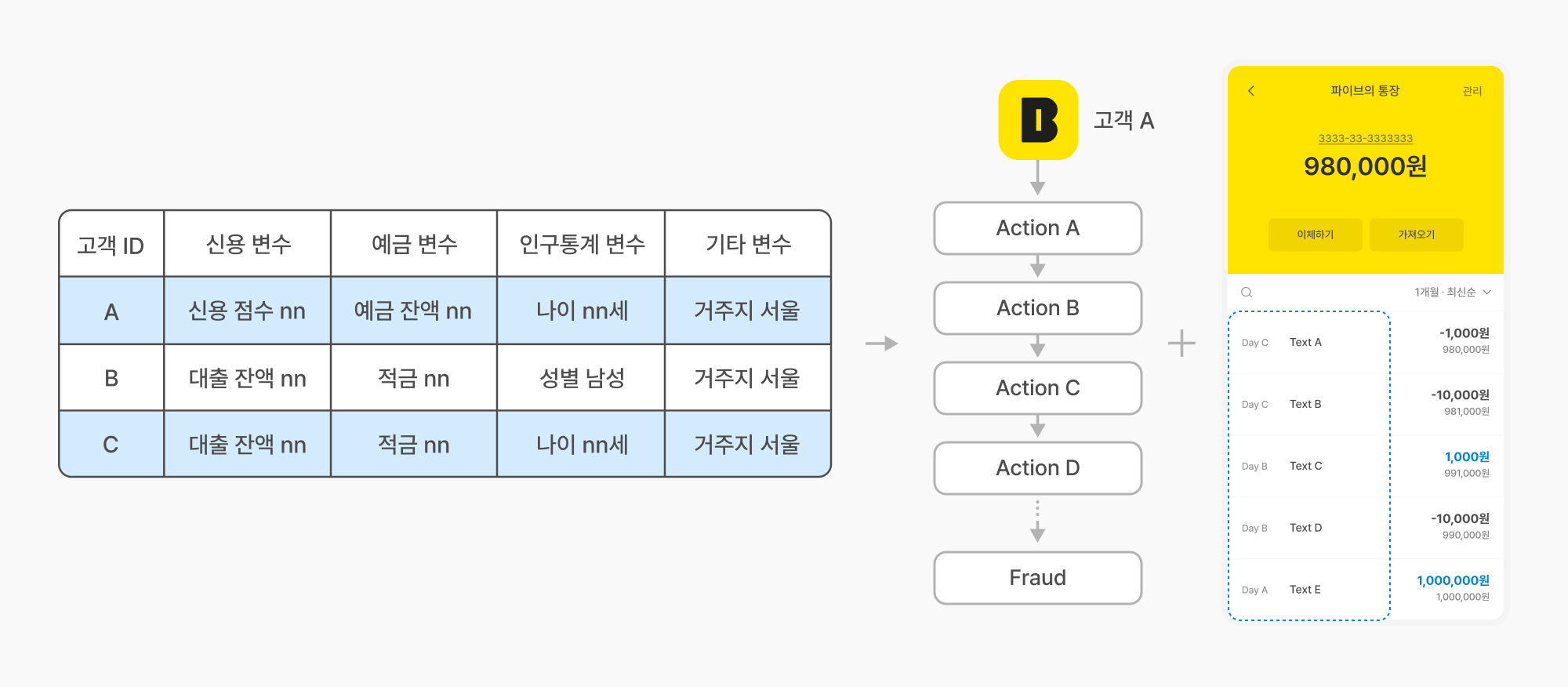
기존 FDS(이상거래탐지시스템) AI 모델이 개별 거래(포인트)에 집중했다면, 새로운 모델은 시간의 흐름에 따른 고객 행동 패턴, 즉 시퀀스에 집중합니다. 보이스피싱은 단일 행위로 이루어지지 않기 때문입니다. 사기범의 지시에 따라 특정 앱을 설치하고, 여러 차례 자금을 이체하는 등 연속적인 행동이 모여 하나의 사기 사건을 만듭니다. 이에 착안해, 저희는 고객의 앱 이용 이력과 거래 내역을 하나의 시퀀스로 묶고, 이 시퀀스 자체가 미래의 보이스피싱 발생 가능성을 얼마나 내포하고 있는지를 예측하고자 했습니다.
Time-series Classification
기존 FDS AI 모델은 포인트 단위로 변수를 생성해 판단하는 분류(Classification) 문제였다면, 새로운 모델은 고객의 시간 흐름에 따라 발생하는 고객의 행동과 거래 데이터를 활용해 시계열 분류(Time Series Classification) 문제로 접근했습니다.
즉, 최소 N개 이상의 이벤트(앱 활동, 거래 등)로 구성된 시퀀스 데이터를 입력받아 해당 시퀀스가 이후에 ‘정상’, ‘사기’, ‘피해’ 중 어떤 클래스에 속할 확률이 높은지를 분류하는 방식입니다. 이를 통해 특정 거래가 발생하기 전이라도 이상 징후를 보이는 연속된 행동 패턴을 기반으로 사기를 미리 예측하고 대응할 수 있게 됩니다.
데이터 구성
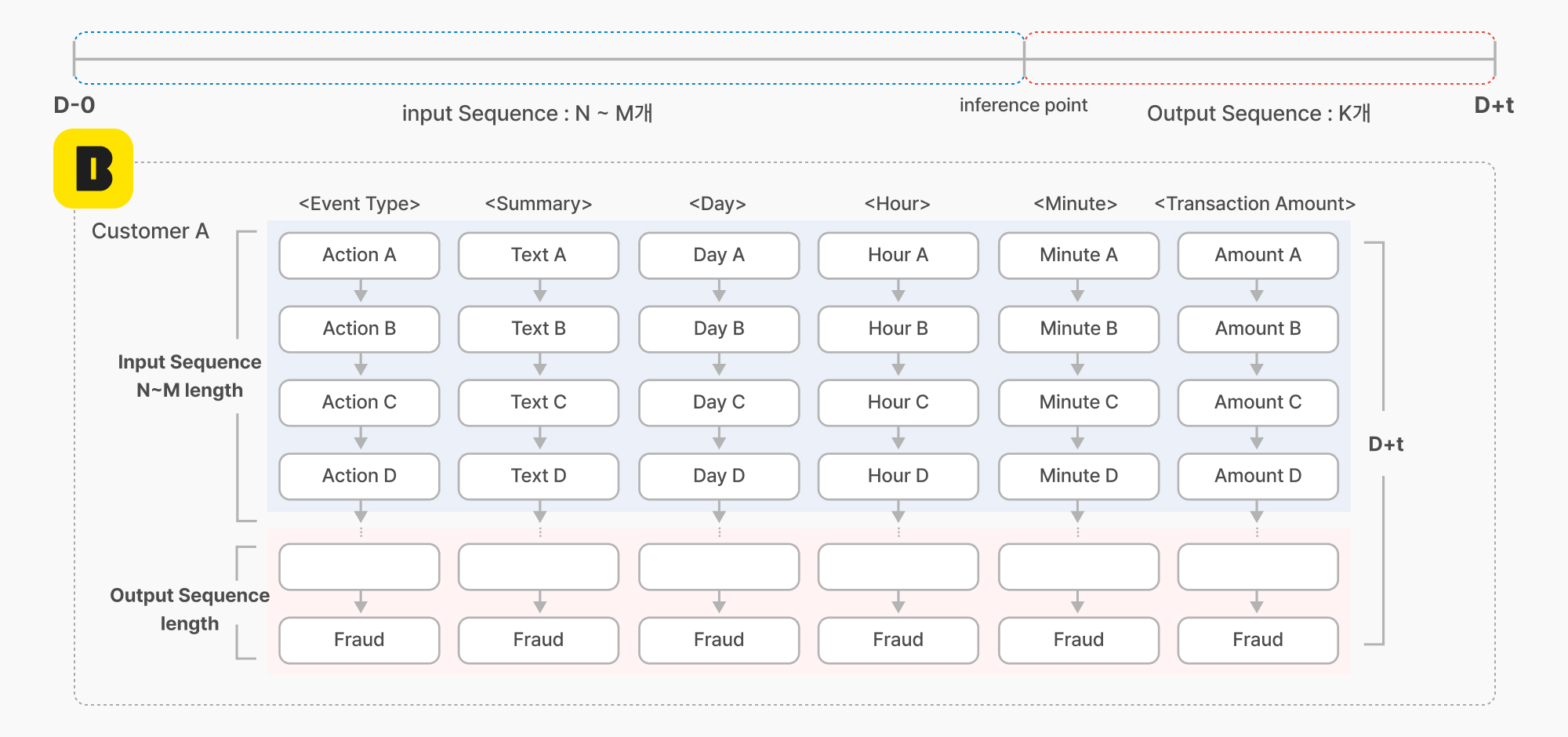
새로운 유형의 사기에도 강건하게 대응하고자 변수 가공(Feature Engineering)을 최소화하고, AI 모델이 데이터로부터 직접 패턴을 학습할 수 있도록 설계했습니다. 이를 위해 고객 행동의 본질을 담은 기본적인 정보들을 그대로 활용했으며, 시계열 데이터의 특성에 맞게 고객의 행동을 시간 순서대로 나열한 시퀀스를 다음 네 가지 핵심 정보로 구성했습니다.
- 행동이 발생한 시간 정보(시, 분, 일자)
- 금융 거래와 관련된 금액 정보
- 거래의 맥락을 담은 텍스트 정보
Vision Transformer (ViT) in Finance
왜 Vision Transformer(ViT)를 선택했는가?
시계열 데이터를 처리할 때 전통적인 시계열 모델(AR, MA, ARIMA 등)이나 LSTM 같은 순환 신경망(RNN) 계열 모델을 고려할 수도 있습니다. 그러나 저희는 이미지 인식 분야에서 어텐션 메커니즘을 활용한 Vision Transformer(ViT) 구조에서 새로운 가능성을 발견했습니다. 그 결과, 각 접근법을 비교·검토한 뒤 아래와 같은 이유로 Vision Transformer 구조를 시계열 데이터에 맞게 변형해 최종 모델을 개발했습니다.
1. 전통적인 시계열 모형 (AR, MA, ARIMA 등)
전통적인 시계열 모형은 통계적 기법을 기반으로 과거 시계열 데이터의 패턴(추세, 계절성, 순환, 불규칙)을 분석하고, 이를 바탕으로 미래 값을 예측합니다. 다만 아래와 같은 한계로 본 과제에는 적합하지 않다고 판단했습니다.
- 보이스피싱은 발생 양상이 다양하고 불규칙하며, 비선형적인 패턴이 많아 단순 통계 모형만으로는 충분히 포착하기 어렵습니다.
2. 순환 신경망 계열 모델 (RNN, LSTM, GRU 등)
순환 신경망 계열 모델은 직전 시점의 정보를 은닉 상태(Hidden State)로 유지하며 순차적으로 데이터를 처리하는 딥러닝 모델입니다. LSTM과 GRU는 기존 RNN의 장기 의존성(Long-term dependency) 문제를 개선한 모델입니다.
LSTM/GRU가 장기 의존성 문제를 개선하긴 했지만, 시퀀스가 매우 길어지면 초반 정보가 희석되거나 소실될 가능성이 여전히 존재합니다. 반면 Transformer의 Self-Attention은 시퀀스 내 모든 시점 간 연관성을 직접 계산할 수 있어 멀리 떨어진 이벤트 간 관계도 더 효과적으로 포착할 수 있습니다.
또한 RNN 계열 모델은 본질적으로 순차 처리가 필요해 GPU 병렬화에 불리합니다. 대규모 데이터를 학습하고, 20ms 내에 다수 요청을 처리해야 하는 요구사항을 고려할 때 성능·효율 측면에서 한계가 있다고 판단했습니다.
3. ViT(Vision Transformer) 모델
ViT(Vision Transformer)는 An Image is Worth 16x16 Words에서 제안된 딥러닝 모델로, 기존에 CNN이 주류였던 이미지 인식 분야에서 이미지를 패치(patch) 단위로 나누어 토큰화한 뒤 Transformer 아키텍처를 적용한 접근입니다. 저희는 아래 이유로 ViT 구조를 기반으로 최종 모델을 선택했습니다.
-
‘거래(point)‘와 ‘시퀀스(sequence)‘를 동시에 보는 관점: ViT는 입력을 여러 개의 패치로 분할해 처리합니다. 이를 시계열 데이터에 적용하면 개별 거래(포인트)뿐 아니라 여러 이벤트 묶음(구간/블록) 간의 관계까지 학습할 수 있습니다. 또한 (필요 시) convolution의 dilation/stride와 유사한 설계를 통해 전통적 시계열 모델이 포착하던 구조를 일부 모방하면서도, 더 넓은 시간적 맥락을 효율적으로 반영할 수 있습니다.
-
Attention 메커니즘의 잠재력: Self-Attention을 적극 활용해 시퀀스 내에서 어떤 이벤트가 보이스피싱 탐지에 더 중요한지를 모델이 스스로 학습하도록 하고자 했습니다.
-
Inductive Bias와 일반화 성능: 순수 Transformer는 선형 계층 중심 구조라 CNN 대비 inductive bias가 약해 일반화 성능을 위해 대규모 데이터가 필요한 경우가 많습니다. 반면 ViT는 패치 구성(국소성, locality) 과 positional encoding(순서/위치 정보) 을 통해 시계열에 유리한 inductive bias를 비교적 명시적으로 부여할 수 있다고 판단했습니다. 그 결과, 상대적으로 제한된 데이터에서도 시계열 특성을 효과적으로 학습하고 더 나은 일반화 성능을 기대할 수 있었습니다.
💡 Inductive Bias란?
모델이 새로운 입력에도 잘 일반화하도록 돕는 사전 가정(구조적 편향) 을 의미합니다. 예를 들어 CNN은 가까운 픽셀 간 관계가 중요하다는 국소성(locality) 가정을(수용영역을 통해) 자연스럽게 갖고 있어, 위치 변화에도 비교적 안정적으로 특징을 학습합니다. RNN은 데이터가 시간 순서(sequentiality)를 따른다는 가정을 내재해 순차 데이터 처리에 강점이 있습니다. 이런 inductive bias는 모델이 모든 규칙을 데이터로만 “처음부터” 학습하지 않아도 되게 만들어, 상대적으로 적은 데이터에서도 안정적인 학습에 도움을 줄 수 있습니다.
ViT 구조의 변형
SOTA(State-of-the-art) 모델인 ViT 구조를 그대로 적용해 학습을 진행하려 했지만, 곧 두 가지 핵심적인 문제에 직면했습니다.
첫째, 이미지와 시계열 데이터의 본질적 차이입니다. ViT가 효과적으로 활용하는 이미지의 지역성(locality) 가정은 인접한 픽셀들이 강한 연관성을 가진다는 전제에 기반합니다. 반면 금융 거래 시퀀스에서는 바로 직전의 데이터뿐 아니라, 시간적으로 멀리 떨어진 과거의 이벤트가 결정적인 단서가 되는 경우가 많습니다. 표준 ViT 구조만으로는 이러한 장기적이고 복잡한 시간적 의존 관계를 충분히 학습하는 데 한계가 있었습니다.
둘째, FDS 데이터의 심각한 클래스 불균형 문제입니다. 저희가 다루는 데이터는 0.1% 이하의 이상거래 (소수 클래스) 를 분류하는 데이터로 구성되어 있습니다. ViT 기본 구조처럼 분류까지 End-to-End로 학습하면, 모델이 손실을 쉽게 줄이기 위해 대부분을 ‘정상’으로 예측하는 쪽으로 쏠리는 경향이 있었고, 이는 소수 클래스 탐지 성능 및 일반화 성능 저하로 이어졌습니다.
이러한 문제를 해결하고 ViT를 금융 FDS 환경에 최적화하기 위해, 저희는 아래와 같이 네 가지 독창적인 구조적 개선을 설계해 적용했습니다.
1. Custom Patch Embedding
학습에 사용한 데이터는 금액과 같은 연속형(Continuous) 피처, 이벤트 유형과 같은 범주형(Categorical) 피처, 그리고 텍스트(Text)가 혼합 되어 있습니다. 각 피쳐의 성격에 맞게 별도로 처리(Linear, Embedding layer 등) 후 결합(Concatenate) 하는 방식이 아닌 하나의 Embedding 구조 로 묶어 패치(Patch)를 생성했습니다. 이를 통해 모델이 다양한 유형의 정보를 종합적으로 고려하여 Multi-Head Attention 연산을 수행하도록 설계했습니다.
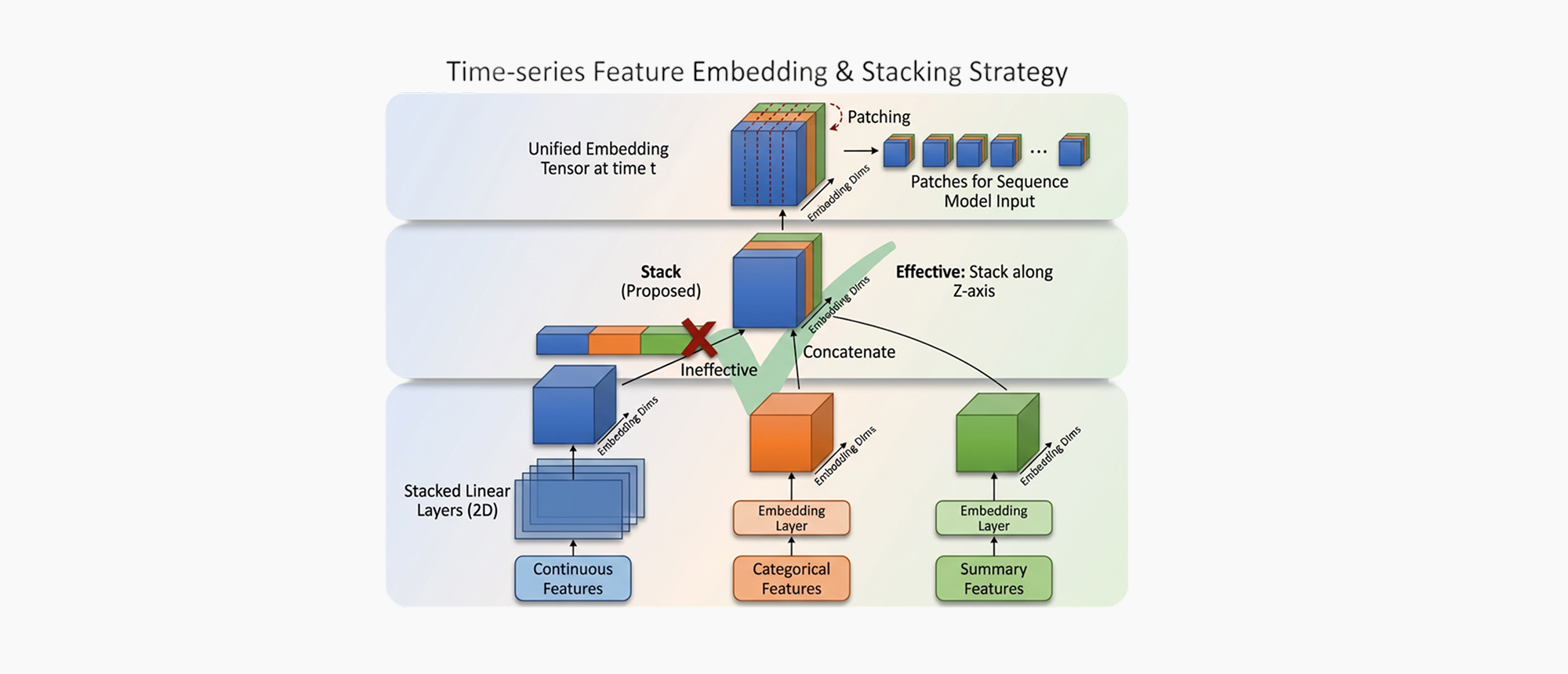
2. Multi-scale Feature Extraction
기존 트랜스포머(Transformer)는 동일한 블록(Block)을 반복적으로 쌓아 표현력을 확장합니다. 반면 저희는 시퀀스에서 서로 다른 dilation(간격)을 갖는 여러 개의 선형 투형(Linear Projection) 기반 패치 경로를 구성하고, 이를 병렬 블록으로 학습시켜 다양한 시간 간격의 이벤트 관계를 동시에 학습하도록 했습니다. 그 결과 인접 이벤트뿐 아니라 시간적으로 멀리 떨어진 이벤트 간 관계까지 한 번에 포착할 수 있었고, multi-scale 시간 패턴을 동시에 반영해 분석 범위를 넓혔습니다.
3. Cross-Attention Layer
Multi-scale 구조에서는 서로 다른 스케일에서 학습된 여러 블록의 출력을 어떻게 결합하느냐가 핵심입니다. 단순 평균/합 같은 연산으로 통합하면, 각 패치에서 학습한 정보가 희석되거나 소실되어 일반화 성능이 떨어질 수 있었습니다. 이를 해결하기 위해 Cross-Attention layer를 도입했습니다. 블록 간 정보를 교환하게 하고, 현재 입력에서 어떤 스케일의 정보가 더 중요한지를 모델이 스스로 가중치로 학습하도록 함으로써 전체 표현력을 강화했습니다.
4. Imbalance 해결을 위한 Metric Learning 기반의 Two-Stage 학습
기존 AI 모델은 입력에 대한 분류 값을 예측하기 위해 End-to-End 방식으로 학습하지만, 이러한 방법은 극심한 클래스 불균형 문제를 완화하기에 한계가 있었습니다. 저희 역시 동일한 문제를 겪었습니다. 학습 데이터가 0.1% 이하 이상 거래데이터로 구성되어 불균형이 매우 심해, 학습 과정에서 손실(loss)이 빠르게 낮아지면서도 평가 데이터에서는 소수 클래스를 제대로 맞추지 못해 일반화 성능이 떨어졌습니다. 이를 해결하기 위해 임베딩 공간에서의 분별력을 높이는 Metric learning을 통해 Representation Learning을 우선적으로 한 후에 (1-Step) Downstream Task를 추가하여 학습을 진행 하였고 그 결과 안정적인 학습이 가능하게 되었습니다.
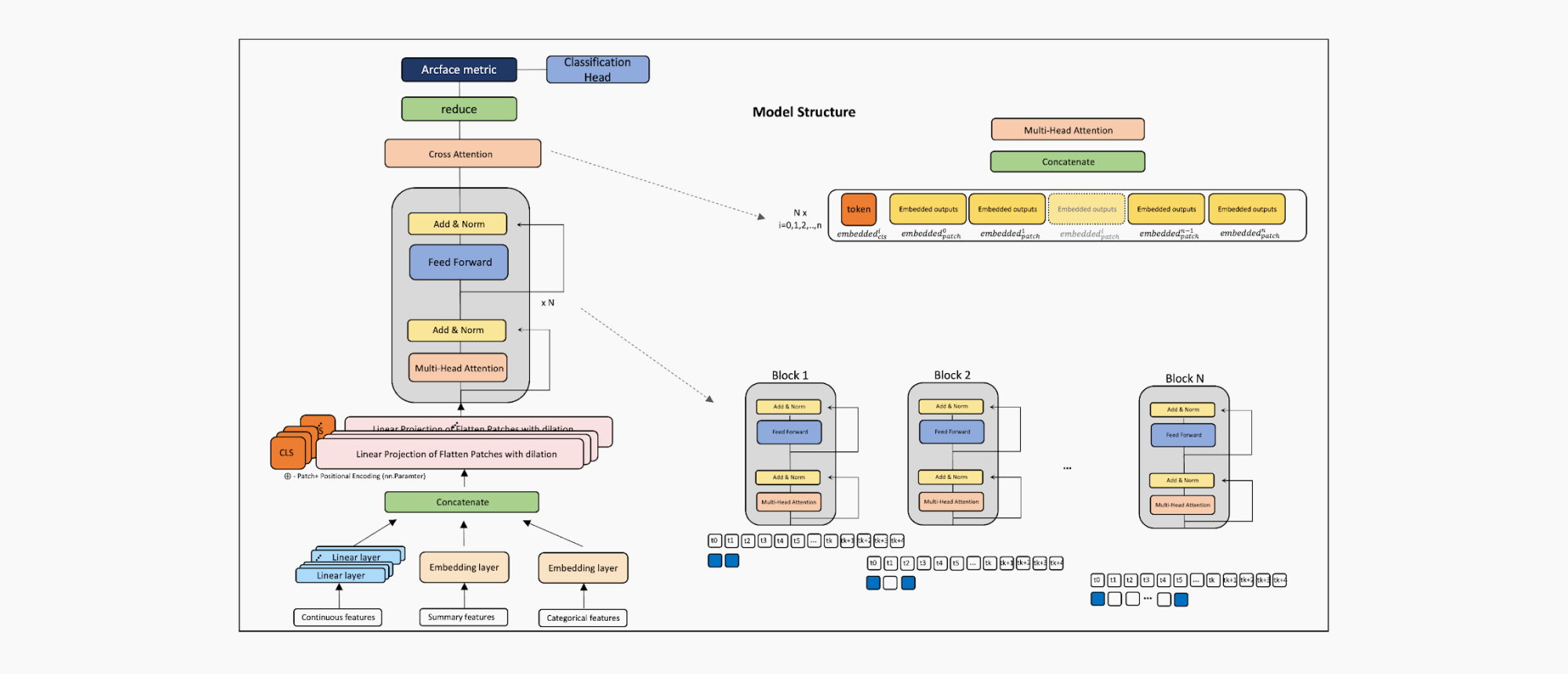
여러 차례의 실험을 통해 최종적으로 위 구조를 확정했으며, 각 구성 요소를 단계적으로 추가할 때마다 성능이 유의미하게 향상되는 것을 확인했습니다. 특히 Metric Learning 손실로는 Arcface: Additive Angular Margin Loss for Deep Face Recognition에서 제안된 방식을 적용했을 때 가장 뛰어난 성능을 보였습니다.
XAI(설명 가능한 AI) 적용
카카오뱅크 FDS는 해석이 명확한 룰(Rule) 기반 탐지와 AI 모델 기반 탐지를 함께 사용합니다. 룰 기반 방식은 “N만원 이상 입금 후 t시간 이내, 타인에게 M만원 이상 이체” 처럼 조건이 명확해 직관적입니다. 반면 AI 모델은 흔히 블랙박스(Black Box)로 불리며, 예측의 판단 근거를 파악하기 어렵다는 한계가 있습니다.
물론 변수(피처) 기반 모델을 설명하기 위한 SHAP(SHapley Additive exPlanations), LIME(Local Interpretable Model-agnostic Explanation) 같은 기법이 널리 사용되고 있으며, 카카오뱅크 역시 이를 연구하고 적용해 왔습니다. cf) XAI 논문, XAI 기술블로그
하지만 원본 데이터(Raw Data)를 직접 학습하는 시퀀스 모델에는 기존의 변수 기반 XAI를 그대로 적용하기가 쉽지 않았습니다. 이를 해결하기 위해 저희는 Jacob Gildenblat이 제안한 Gradient Attention Rollout 기법을 활용하여 XAI를 도입하고자 했습니다.
Gradient Attention Rollout : Jacob Gildenblat이 Attention Rollout을 확장한 기법으로, 특정 클래스 예측에 어떤 토큰이 중요하게 적용했는지를 더 명확히 보여줍니다. Attention Rollout이 클래스와 무관한 전반적 어텐션 흐름을 제공한다면, Gradient Attention Rollout 기법은 예측 대상 클래스의 로짓(logit)을 기준으로 각 어텐션 레이어에 대한 그래디언트를 계산하고, 이를 어텐션에 반영해 해당 클래스 예측과 관련성이 높은 어텐션만을 강조한 맵을 생성합니다.
이를 통해 모델이 ‘사기’라고 판단했을 때 입력된 고객 행동 시퀀스 중 어떤 구간(Patches)에 집중하여 그런 결정을 내렸는지를 시각적인 ‘히트맵(Heatmap)’ 형태로 확인할 수 있게 되었습니다.
⚠️ 아래는 당행에서 발생한 투자사기관련 신고 접수된 고객에 대해 모델이 탐지를 하였고, 이 때 모델 결과에 영향을 준 구간(Patches)들을 표현한 예시입니다.
- "17시 경 O만원 이상 타인으로부터 입금, 동시에 로그인 발생"
- "17시 경 O만원 이상 타인에게 이체, 17시 경 O만원 이상 타인으로부터 입금"
- "17시 경 0만원 이상 외국인(A국가)에게 이체, 17시 경 0만원 이상 외국인(A국가)에게 이체"
Dilation = 2일 경우 상위 어텐션 가중치를 가지는 패치들 - "16시 경 로그인 발생, 동시에 타인에게 O만원 이상 이체"
- "16시 경 O만원 이상 타인에게 입금, 17시 경 O만원 이상 타인에게 입금"
- "15시 경 O만원 이상 외국인(A국가)에게 이체, 16시 경 O만원 이상 타인으로부터 입금"
...
모델 성능과 서빙 시스템
모델 성능 검증
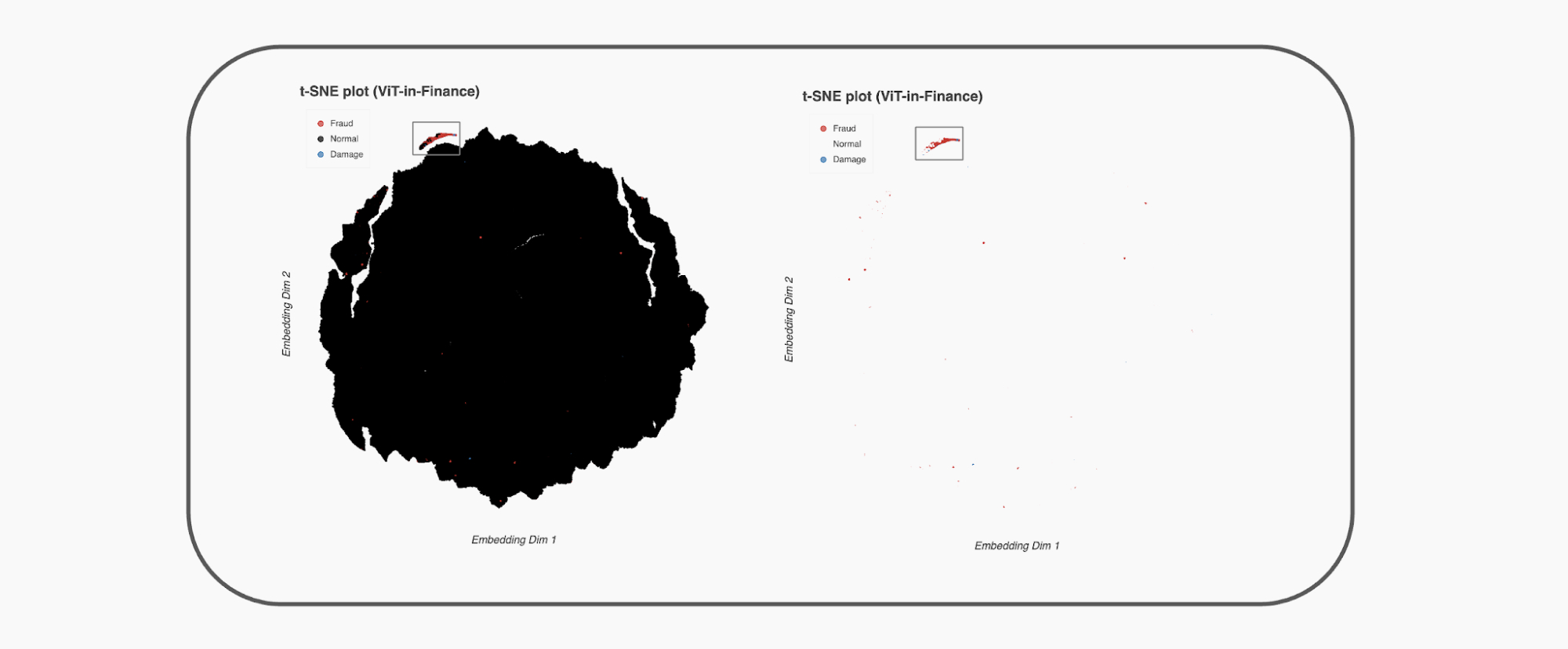
학습 데이터, 평가 데이터의 경우 0.1% 이하 이상 거래데이터로 구성 되어 있어 클래스 불균형이 매우 심합니다. 그럼에도 임베딩 벡터를 t-SNE로 시각화했을 때, 사기 관련 클래스가 특정 영역에 군집을 형성하는 것을 확인했습니다. 이는 모델이 정상 패턴과 사기 패턴을 의미 있게 분리해 학습했음을 시사합니다.
실시간 서빙 아키텍처
모델 성능만큼 중요한 과제는 모든 고객에게 빠르고 안정적으로 적용하는 것이었습니다. 저희는 특정 조건의 고객만 필터링해 모니터링하던 기존 방식에서 벗어나, 카카오뱅크를 이용하는 모든 고객을 대상으로 24시간 실시간 탐지를 수행하는 것을 목표로 했습니다.
기존에 Logan이 구축했던 FDS AI 서비스를 기반으로, 서빙 파이프라인을 한층 더 고도화했습니다.
-
실시간 데이터 전처리: Apache Flink 기반 데이터 파이프라인이 초당 수백만 건의 로그를 실시간으로 수집해 고객별 시퀀스 형태로 가공합니다. 이 파이프라인은 하루 최소 2억 8,800만 건 이상의 레코드를 지연 없이 처리합니다.
-
Triton 모델 추론: 가공된 시퀀스 데이터는 NVIDIA Triton Inference Server 기반 추론 시스템으로 전달됩니다. GPU 서빙 환경으로 전환한 뒤, 일평균 1,800만 건 수준의 요청에 대해 평균 20ms 이내의 낮은 레이턴시를 달성했습니다.
- 추론값 활용 및 모니터링: 추론 결과는 Kafka Topic에 적재되며, 이후 FDS 현업부서에서 정의한 추가 조건과 결합됩니다. 최종적으로 통합 단말 화면에 모니터링 대상자를 제공합니다.
이 시스템을 통해 매일 카카오뱅크 하루 평균 이용 고객의 약 30%를 보이스피싱 위협으로부터 지속적으로 모니터링하고 있습니다.
마무리하며
지금까지 고도화되는 보이스피싱 위협에 대응하기 위해 카카오뱅크가 탐지 패러다임을 어떻게 전환하고 AI 기술을 어떻게 활용했는지 소개했습니다.
보이스피싱 예방은 흔히 풍선 효과로 비유합니다. 한쪽을 누르면 다른 한쪽이 부풀어 오르는 풍선처럼, 특정 은행이 탐지 시스템을 강화하면 범죄자들은 상대적으로 취약한 다른 금융사를 노리는 경향이 있습니다. 이런 이유로 개별 금융사의 노력만으로는 사회 전체의 보이스피싱 피해를 근본적으로 막기 어렵습니다. 모든 금융사가 각자의 노하우를 공유하고 유기적으로 협력해야만, 범죄의 고리를 끊고 더 촘촘한 사회적 안전망을 구축할 수 있다고 생각합니다.
이러한 문제의식 아래 금융위원회는 ASAP(AI-based anti-phishing Sharing & Analysis Platform) 플랫폼을 출범했으며, 카카오뱅크는 금융보안원·케이뱅크·토스뱅크와 함께 연합학습(Federated Learning) 모델을 구축하고 있습니다. 이 협력은 개별 은행의 데이터를 외부에 노출하지 않으면서도 각 사의 탐지 노하우와 패턴을 공동의 모델에 학습시켜 금융권 전반의 방어 수준을 한 단계 끌어올리는 것을 목표로 합니다.
물론 카카오뱅크의 노력은 여기서 멈추지 않습니다. 앞으로도 다음과 같은 로드맵에 따라 보이스피싱 탐지 시스템을 지속적으로 고도화해 나갈 계획입니다.
-
지속적인 모델 고도화: MLOps 환경에서 새로운 사기 패턴을 지속적으로 학습(Continual Learning)하고 성능을 개선합니다.
-
그래프 기반 탐지 모델: 자금 흐름과 관계망을 분석하는 그래프(Graph) 기반 모델을 도입해 더욱 정교한 탐지를 시도합니다.
-
LLM·멀티모달 기반 파운데이션 모델: 고객 행동 패턴뿐 아니라 상담 내용(음성/텍스트) 등 다양한 형태의 데이터를 함께 분석하는 멀티모달(Multi-modal) 파운데이션 모델을 연구해 한층 고도화된 보이스피싱 탐지 모델을 개발하고자 합니다.
긴 글 읽어주셔서 감사합니다.
